Andrew Bosland
Analysis Report
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
analysis_samp = "output/analysis_sample.csv"
analysis_sample = pd.read_csv(analysis_samp)
Abstract
Using two different dictionaries of positive and negative sentiment words and the S&P 500 companies, this code pulls the 10-Ks and stock returns for the respective companies and compares overall sentiments in 10-Ks to stock returns. The NEAR_regex function in python was extremely helpful in calculating the counts of positive and negative sentiments. In addition to finding out the overall positive and negative sentiments for the 10-Ks we also looped through each 10-K to find out how often certain words appeared next to positive and negative sentiment words and their specific effects on the stock returns in the days shortly after. Specifically, I searched for words along the topics of Porters (Sales, Suppliers, Customers, Employees, etc.), Tech (Computers, Robots, AI, Technology, etc.) and Risk (Inflation, Supply Chains, Natural Disasters, Pandemic, etc.) I found that there was overall a negative correlation with the stock prices even if they were positive words. The main outlier I found that was when Tech was talked about in a negative way there was an extremely high positive correlation with the stock price. In the report below I will get into more detail surrounding specific instances and will visualize the results in order to make patterns more prevalent.
Variables
Return
The initial sample used was the S&P 500.
The return variables were built and modified using the NEAR_Regex function in python. To begin, I had to load in the four sentiment dictionaries bhr_negative = pd.read_csv('inputs/ML_negative_unigram.txt',header=None)[0].to_list() and properly format them in regex formatting using this bhr_neg_reg = '('+'|'.join(bhr_negative)+')'. From here, I had to load in the sample (S&P500) and and loop through the entire index and extract all of the correlating 10-K HTML files. I then used a function called BeautifulSoup, which can be imported using from bs4 import BeautifulSoup, in order to clean all of the HTML files and put them into proper format to be used with NEAR_regex. Finally,I used the NEAR_regex function ML_Pos = len(re.findall(NEAR_regex([bhr_pos_reg]), cleaned))/len(cleaned) and calculated the percentage of positive and negative sentiment words in each 10-K. To add a new column for each variable to the sp500 data frame I then used sp500.loc[index, 'ML_Pos'] = ML_Pos.
Sentiment
The sentiment variables were created in a similar fashion as the return variables except for this line Porter_Pos = len(re.findall(NEAR_regex(['(Sales|suppliers|customers|employees|investment|innovation)',bhr_pos_reg],5), cleaned))/len(cleaned) which was a slightly more complicated NEAR_regex function. Initially I struggled with the order in which to put the lists and punctuation but after some alterations I was able to obtain a working function that produced results that made sense.
Topics
I chose the 3 topics I did for my “contextual sentiment” measures because I wanted three extremely different lists. I was particularly interested in technology and its effect because every single day technology is growing more and more important in society. Second, I wanted to see how risks in particular effected the stock returns because we had just recently lived through a pandemic that largely impacted the economy so how they were correlated. Lastly, I chose the Porters list because I wanted to do a list that I believed would have a large amount of hits in each 10-K in order to vary my results.
Eye Test
My “contextual sentiment” variables pass the eye test, there is nothing fishy, plenty of variation in measure (nothing is almost all 0), and the industries I expect to be talking positively or negatively are (i.e. Risk has a higher negative than positive)
Summary Stats
When looking at my summary stats, right away the first that jumps out is that there is only 652 rows in the data frame. Unfortunately when running my code for the producing the calculated returns I was only able to get my code to work using the line unique_file_dates = returns_sp500[‘file_date’].unique(). I am aware that this then means that I will only be using the firms in my sample that had unique filing dates but everything else I tried, including taking out the .unique and trying an index, row loop, almost broke my computer. In the end, I still believe the 85 firms data is still enough to produce results that are able to be analyzed. The only problem I see with the analysis as a result of the missing firms is that we will not be able to see firms and their market responses for the the same any 2 periods. Besides the clear missing data, I also was only able to produce cumulative returns for T-T+2 and T+3-T+10 but was not able to only make it properly count just business days. When looking at the summary stats themselves it is interesting to see that the average 7-day returns and 2-day returns following the release of the 10-K was positive. In addition, it is important to note that the cumulative returns are centered around 1 in my analysis, therefore any cumulative returns below 1 would be a negative returns for that period and anything above 1 is a positive return for that period. When looking at the ML vs the LM it is clear that there were more “hits” from the NEAR_regex function, which is interesting because the ML positive and negative dictionaries was shorter and consisted of less words which initially I thought would result in less hits.
analysis_sample.describe()
| Unnamed: 0 | CIK | ML_Pos | ML_Neg | LM_Pos | LM_Neg | Porter_Pos | Porter_Neg | Risk_Pos | Risk_Neg | ... | cash_a | xrd_a | dltt_a | invopps_FG09 | sales_g | dv_a | short_debt | ret | 7-day | 2-day | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 652.00000 | 6.520000e+02 | 652.000000 | 652.000000 | 652.000000 | 652.000000 | 652.000000 | 652.000000 | 652.000000 | 652.000000 | ... | 621.000000 | 621.000000 | 621.000000 | 579.000000 | 621.000000 | 621.000000 | 621.000000 | 652.000000 | 652.000000 | 189.000000 |
| mean | 325.50000 | 7.886351e+05 | 0.024872 | 0.026541 | 0.005225 | 0.016356 | 0.001691 | 0.001984 | 0.000156 | 0.000311 | ... | 0.136487 | 0.032530 | 0.317128 | 2.922886 | 0.160558 | 0.028915 | 0.086618 | 0.002387 | 1.027581 | 1.018590 |
| std | 188.36047 | 5.789311e+05 | 0.002504 | 0.002885 | 0.001105 | 0.003227 | 0.000600 | 0.000589 | 0.000167 | 0.000255 | ... | 0.108716 | 0.044193 | 0.179615 | 1.903650 | 0.156834 | 0.025016 | 0.062808 | 0.025945 | 0.086147 | 0.065624 |
| min | 0.00000 | 2.969000e+03 | 0.019389 | 0.017226 | 0.003061 | 0.008865 | 0.000678 | 0.000286 | 0.000000 | 0.000017 | ... | 0.003713 | 0.000000 | 0.032278 | 0.481436 | -0.082577 | 0.000000 | 0.004306 | -0.078376 | 0.822205 | 0.882648 |
| 25% | 162.75000 | 1.004930e+05 | 0.023044 | 0.024399 | 0.004435 | 0.014318 | 0.001258 | 0.001655 | 0.000050 | 0.000137 | ... | 0.049990 | 0.000000 | 0.189640 | 1.509511 | 0.047763 | 0.006395 | 0.034633 | -0.010641 | 0.976446 | 0.982656 |
| 50% | 325.50000 | 8.292240e+05 | 0.024972 | 0.026349 | 0.005230 | 0.015759 | 0.001635 | 0.001993 | 0.000111 | 0.000242 | ... | 0.111474 | 0.007159 | 0.301803 | 2.449015 | 0.113672 | 0.025933 | 0.067911 | 0.001115 | 1.016476 | 1.008368 |
| 75% | 488.25000 | 1.140859e+06 | 0.026500 | 0.028663 | 0.005846 | 0.018256 | 0.002100 | 0.002372 | 0.000193 | 0.000409 | ... | 0.210811 | 0.061962 | 0.384653 | 3.930926 | 0.220771 | 0.045559 | 0.125555 | 0.013475 | 1.056125 | 1.034890 |
| max | 651.00000 | 1.757898e+06 | 0.030676 | 0.034878 | 0.008642 | 0.026658 | 0.003226 | 0.003675 | 0.001087 | 0.001198 | ... | 0.444828 | 0.174006 | 1.007041 | 9.348215 | 0.652428 | 0.103745 | 0.256825 | 0.310995 | 1.371429 | 1.348567 |
8 rows × 81 columns
Discussion Questions
#1 Compare / contrast the relationship between the returns variable and the two “LM Sentiment” variables (positive and negative) with the relationship between the returns variable and the two “ML Sentiment” variables (positive and negative). Focus on the patterns of the signs of the relationships and the magnitudes.
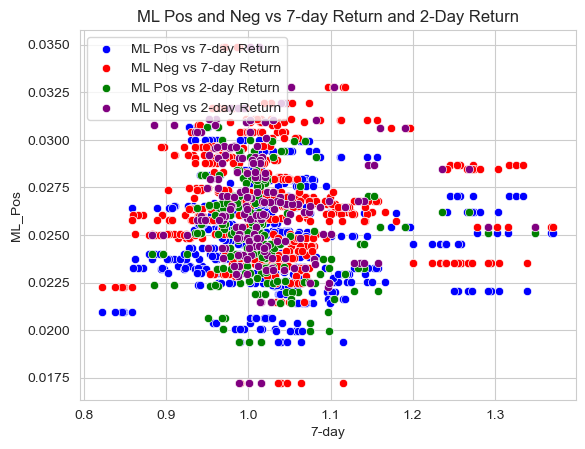
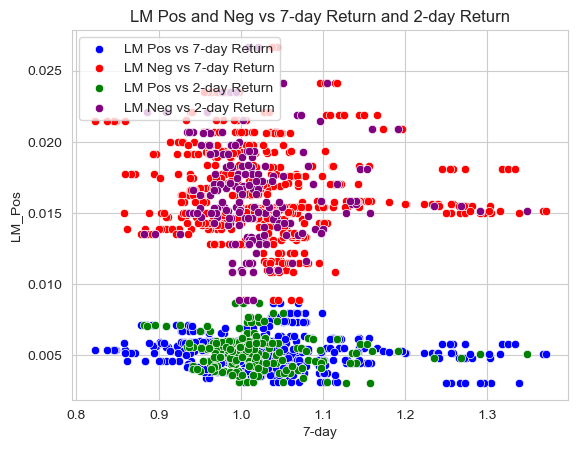
The “LM Sentiment” variable has an odd relationship with the 7-Day return because the LM negative is always greater than the LM positive whether the return is high or low. If you look below at the correlation table, you can see that the LM_Neg and LM_Pos variables have a higher negative correlation with the stock returns, which would make sense based on my findings. It is interesting to note that LM_Pos actually has a higher negative correlation than LM_Neg which is not what I expected to find. When looking at the “ML Sentiment” variables and the relationship with the 7-Day returns variable, it is actually opposite to what I would have expected as well. The stocks that saw the highest returns in the period of T+3-T+10 days where T was the 10-K filing date actually had more “hits” for negative words throughout their 10-K which was surprising. I believe there is more of a true effect on stock returns from the “ML Sentiment” variables. Unlike the LM_Pos and LM_Neg, the ML_Neg has a higher negative correlation than ML_Pos. Ultimately, I was surprised to find that all 4 had a negative correlation with the the 7-Day returns and from looking at the graphs, I believe that the negative sentiment words have no statistically significant effect on returns because most of the high returns have a high negative sentiment.
#2 If your comparison/contrast conflicts with Table 3 of the Garcia, Hu, and Rohrer paper (ML_JFE.pdf, in the repo), discuss and brainstorm possible reasons why you think the results may differ. If your patterns agree, discuss why you think they bothered to include so many more firms and years and additional controls in their study? (It was more work than we did on this midterm, so why do it to get to the same point?)
My comparison/contrast is different than table 3 of the Garcia, Hu and Rohrer paper mainly because I had to use a smaller sample size (i.e. 85 firms) because my code would not work otherwise. Additionally, another reason our findings could be different is the time of the year they did the study and the current market situation. Another possibility is the specific 10-Ks they pulled could have been particularly more positive or negative and could have had different effects on the market at that time. Some of the findings they had, I had as well, such as LM Positive sentiment words had a negative effect on stock returns which agrees with my findings. In addition, I hypothesized that the negative sentiment words do not have a significant effect on stock returns which is in line with their findings as well.
#3 Discuss your 3 “contextual” sentiment measures. Do they have a relationship with returns that looks “different enough” from zero to investigate further? If so, make an economic argument for why sentiment in that context can be value relevant.
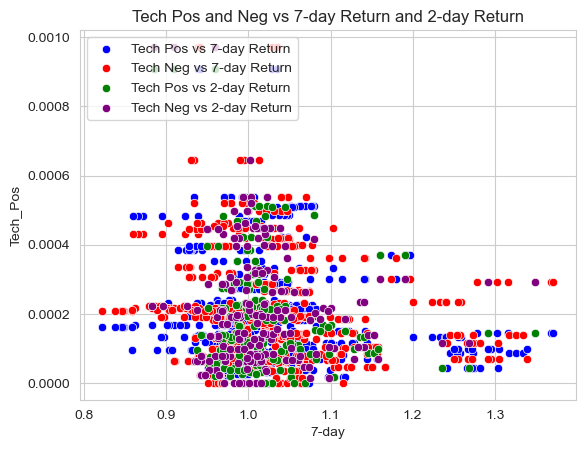
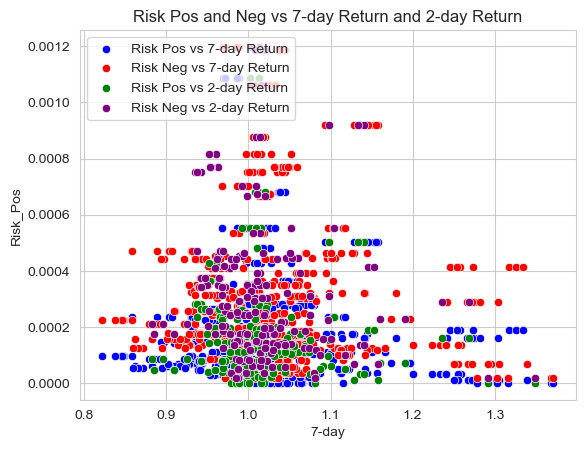
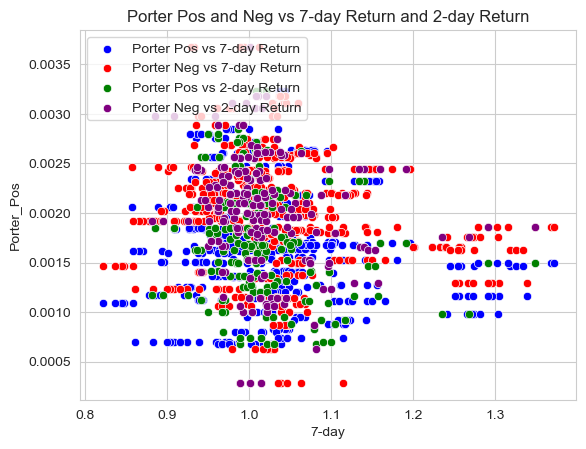
My “contextual” sentiment measures have a relationship with returns that looks “different enough” from zero to investigate further. I believe two of three of my measures should be investigated further. First, Porter’s list of words having a -.134123 and -.179894 correlation with returns is the farthest away from 0 and I believe this is because it is a list that talks about employees and customers of the company and therefore if they are talked about in a negative way economically it should have a negative effect on stock returns. The second one that should be investigated further is Tech because of the extremely high negative correlation with returns both positive and negative as well. A -.165168 and -0.160903 correlation for the Tech_Pos is extremely high for what is supposed to be a positive effect on stock returns.
#4 Is there a difference in the sign and magnitude? Speculate on why or why not. There is a large difference in the magnitude between the 7-day and 2-Day when looking at the correlation between them and the “ML Sentiment” variable. I believe this is largely in part due to the immediate response on the day of and in the 2 days following the release of the 10-K by companies, and the further out you look there will be less and less of a correlation between the sentiment of the 10-Ks and the stock returns. However, there is no sign difference, there is still a negative correlation between the 7-Day and 2-Day returns and the “ML Sentiment” variables.
Correlation Matrix
| | 7-day | 2-Day | |———-|———-|———-| | ML_Pos | -0.015989 | -0.086373 | | ML_Neg | -0.039233 | -0.087719 | | LM_Pos | -0.121103 | -0.148118 | | LM_Neg | -0.063470 | -0.070893 | | Porter_Pos | -0.105408 | -0.213354 | | Porter_Neg | -0.134123 | -0.179894 | | Risk_Pos | -0.064131 | -0.094806 | | Risk_Neg | -0.060263 | -0.128890 | | Tech_Pos | -0.165168 | -0.160903 | | Tech_Neg | -0.146511 | -0.113529 |
ML Pos and Neg vs 7-Day Return and 2-Day Return
sns.set_style("whitegrid")
# create a scatter plot with four different colors
sns.scatterplot(data=analysis_sample, x="7-day", y="ML_Pos", color='blue', label='ML Pos vs 7-day Return')
sns.scatterplot(data=analysis_sample, x="7-day", y="ML_Neg", color='red', label='ML Neg vs 7-day Return')
sns.scatterplot(data=analysis_sample, x="2-day", y="ML_Pos", color='green', label='ML Pos vs 2-day Return')
sns.scatterplot(data=analysis_sample, x="2-day", y="ML_Neg", color='purple', label='ML Neg vs 2-day Return')
# add title and legend
plt.title('ML Pos and Neg vs 7-day Return and 2-Day Return')
plt.legend(loc='upper left')
<matplotlib.legend.Legend at 0x7fead8a5f850>
LM Pos and Neg vs 7-Day Return and 2-Day Return
sns.set_style("whitegrid")
# create a scatter plot with four different colors
sns.scatterplot(data=analysis_sample, x="7-day", y="LM_Pos", color='blue', label='LM Pos vs 7-day Return')
sns.scatterplot(data=analysis_sample, x="7-day", y="LM_Neg", color='red', label='LM Neg vs 7-day Return')
sns.scatterplot(data=analysis_sample, x="2-day", y="LM_Pos", color='green', label='LM Pos vs 2-day Return')
sns.scatterplot(data=analysis_sample, x="2-day", y="LM_Neg", color='purple', label='LM Neg vs 2-day Return')
# add title and legend
plt.title('LM Pos and Neg vs 7-day Return and 2-day Return')
plt.legend(loc='upper left')
<matplotlib.legend.Legend at 0x7fead8a6fa30>
Risk Pos and Neg vs 7-Day Return and 2-Day Return
sns.set_style("whitegrid")
# create a scatter plot with four different colors
sns.scatterplot(data=analysis_sample, x="7-day", y="Risk_Pos", color='blue', label='Risk Pos vs 7-day Return')
sns.scatterplot(data=analysis_sample, x="7-day", y="Risk_Neg", color='red', label='Risk Neg vs 7-day Return')
sns.scatterplot(data=analysis_sample, x="2-day", y="Risk_Pos", color='green', label='Risk Pos vs 2-day Return')
sns.scatterplot(data=analysis_sample, x="2-day", y="Risk_Neg", color='purple', label='Risk Neg vs 2-day Return')
# add title and legend
plt.title('Risk Pos and Neg vs 7-day Return and 2-day Return')
plt.legend(loc='upper left')
<matplotlib.legend.Legend at 0x7fead8c9dcd0>
Porter Pos and Neg vs 7-Day Return and 2-Day Return
sns.set_style("whitegrid")
# create a scatter plot with four different colors
sns.scatterplot(data=analysis_sample, x="7-day", y="Porter_Pos", color='blue', label='Porter Pos vs 7-day Return')
sns.scatterplot(data=analysis_sample, x="7-day", y="Porter_Neg", color='red', label='Porter Neg vs 7-day Return')
sns.scatterplot(data=analysis_sample, x="2-day", y="Porter_Pos", color='green', label='Porter Pos vs 2-day Return')
sns.scatterplot(data=analysis_sample, x="2-day", y="Porter_Neg", color='purple', label='Porter Neg vs 2-day Return')
# add title and legend
plt.title('Porter Pos and Neg vs 7-day Return and 2-day Return')
plt.legend(loc='upper left')
<matplotlib.legend.Legend at 0x7fead8cffbb0>
Tech Pos and Neg vs 7-Day Return and 2-Day Return
sns.set_style("whitegrid")
# create a scatter plot with four different colors
sns.scatterplot(data=analysis_sample, x="7-day", y="Tech_Pos", color='blue', label='Tech Pos vs 7-day Return')
sns.scatterplot(data=analysis_sample, x="7-day", y="Tech_Neg", color='red', label='Tech Neg vs 7-day Return')
sns.scatterplot(data=analysis_sample, x="2-day", y="Tech_Pos", color='green', label='Tech Pos vs 2-day Return')
sns.scatterplot(data=analysis_sample, x="2-day", y="Tech_Neg", color='purple', label='Tech Neg vs 2-day Return')
# add title and legend
plt.title('Tech Pos and Neg vs 7-day Return and 2-day Return')
plt.legend(loc='upper left')
<matplotlib.legend.Legend at 0x7fead90d0a00>